- 최초 작성일: 2026-06-07
- 최종 수정일: 2026-06-07
- 조회수: 221 회
- 작성자: 권현욱 (엑셀러)
- 강의 제목: 대용량 데이터도 거뜬! 번개처럼 빠른 초고속 Excel 조회 함수 4가지
들어가기 전에
엑셀을 활용해 방대한 양의 데이터를 다루다 보면 어느 순간 화면이 멈추거나 수식 계산 속도가 눈에 띄게 느려지는 답답한 경험을 마주하게 됩니다. 특히 실무에서 자주 쓰이는 데이터 조회(Lookup) 수식들이 수만 행의 데이터와 만나면 그런 경향이 잦습니다.
수십 분씩 걸리는 데이터 조회 작업 때문에 화면만 보며 마냥 기다리는 경우도 있죠. 이제 효율이 떨어지는 수식에서 벗어나 방대한 스프레드로 가득 찬 대용량 파일도 번개처럼 빠르게 처리해 주는 초고속 엑셀 구조를 배워보세요. 본 강의에서는 기존 VLOOKUP의 한계를 뛰어넘는 최신 함수부터, 데이터 처리 속도를 극대화하는 조합 기법까지, 실무자라면 반드시 알아야 할 '초고속 데이터 조회 함수 4가지 활용법'을 소개합니다.

- 최신 글을 불러오는 중...

📘 권현욱(엑셀러) 신간
퇴근이 빨라지는 제미나이 & 노트북LM 업무자동화 정석: 엑셀 X AI
제미나이 기반 엑셀 VBA 자동화부터 노트북LM 지식 베이스 구축까지, AI 시대 직장인의 무기를 한 권에 담았습니다.
상세 보기대용량 데이터도 거뜬! 번개처럼 빠른 초고속 Excel 조회 함수 4가지
1. XLOOKUP: VLOOKUP을 완벽하게 대체하는 차세대 표준 함수
직장인들이 엑셀을 배우면서 가장 먼저 접하는 조회 함수는 단연 VLOOKUP라고 할 수 있습니다. 하지만 대용량 데이터나 복잡하게 얽힌 실무 테이블에서 VLOOKUP을 사용하려면 여러 가지 제약과 마주치게 됩니다. 대표적인 단점은 '내가 찾고자 하는 기준 열(Key)'이 반드시 '가져올 데이터 열'의 왼쪽에 위치해야만 한다는 점입니다. 이 때문에 데이터를 조회하기 위해 멀쩡한 원본 표의 열 순서를 바꾸거나 열을 통째로 복사해 이동시키는 번거로운 작업을 실무에서 하곤 합니다.
오피스 365(현 Microsoft 365) 버전에서 도입된 XLOOKUP 함수는 이러한 VLOOKUP의 한계를 완벽하게 해결해 줍니다. XLOOKUP은 데이터의 배치 순서에 구애를 받지 않습니다. 기준이 되는 조회 열과 결과값을 반환할 열을 각각 독립된 범위로 따로 선택하기 때문입니다. 덕분에 데이터를 다시 정렬하거나 구조를 훼손하지 않고도 조회 열의 왼쪽에 있는 데이터까지 막힘없이 읽어올 수 있습니다.
기본적인 XLOOKUP의 구문 구조와 매개변수의 의미는 다음과 같습니다.
=XLOOKUP(lookup_value, lookup_array, return_array, [if_not_found], [match_mode], [search_mode])- lookup_value: 찾으려고 하는 기준 값입니다.
- lookup_array: 기준 값을 검색할 단일 열 또는 단일 행 범위입니다.
- return_array: 최종적으로 결과값을 가져올 범위나 배열입니다.
- [if_not_found]: (선택사항) 데이터를 찾지 못했을 때 표시할 사용자 지정 메시지나 값을 지정합니다. 과거에 오류를 숨기기 위해 IFNA나 IFERROR 함수를 중첩하던 번거로움을 완전히 없애줍니다.
- [match_mode]: (선택사항) 정확한 일치(0), 대략적인 일치(-1 또는 1), 와일드카드 문자 매칭(2) 등 일치 방식을 정밀하게 제어합니다.
- [search_mode]: (선택사항) 데이터를 첫 번째 항목부터 찾을지(1), 마지막 항목부터 역순으로 찾을지(-1) 검색 방향을 결정합니다.
실무에서 자주 발생하는 인사 관리 예시를 통해 살펴보겠습니다. 직원의 사내 이메일 주소 데이터를 가지고 해당 직원의 성명을 찾아야 하는 상황입니다. 원본 표를 확인해 보니 '성명' 열(B열)이 기준이 되는 '이메일' 열(F열)보다 왼쪽에 위치하고 있습니다. VLOOKUP 구조라면 수식이 아예 작동하지 않거나 열을 강제로 옮겨야 하지만, XLOOKUP을 사용하면 원본을 그대로 둔 채 깔끔하게 해결할 수 있습니다.
예를 들어, J2 셀에 조회하고자 하는 직원의 이메일 주소를 입력해 두었고, 인사 데이터 시트의 F열 전체가 사내이메일 목록이며, B열 전체가 직원들의 성명 목록일 때 다음과 같이 수식을 작성합니다.
=XLOOKUP(J2, F:F, B:B, "등록되지 않은 이메일")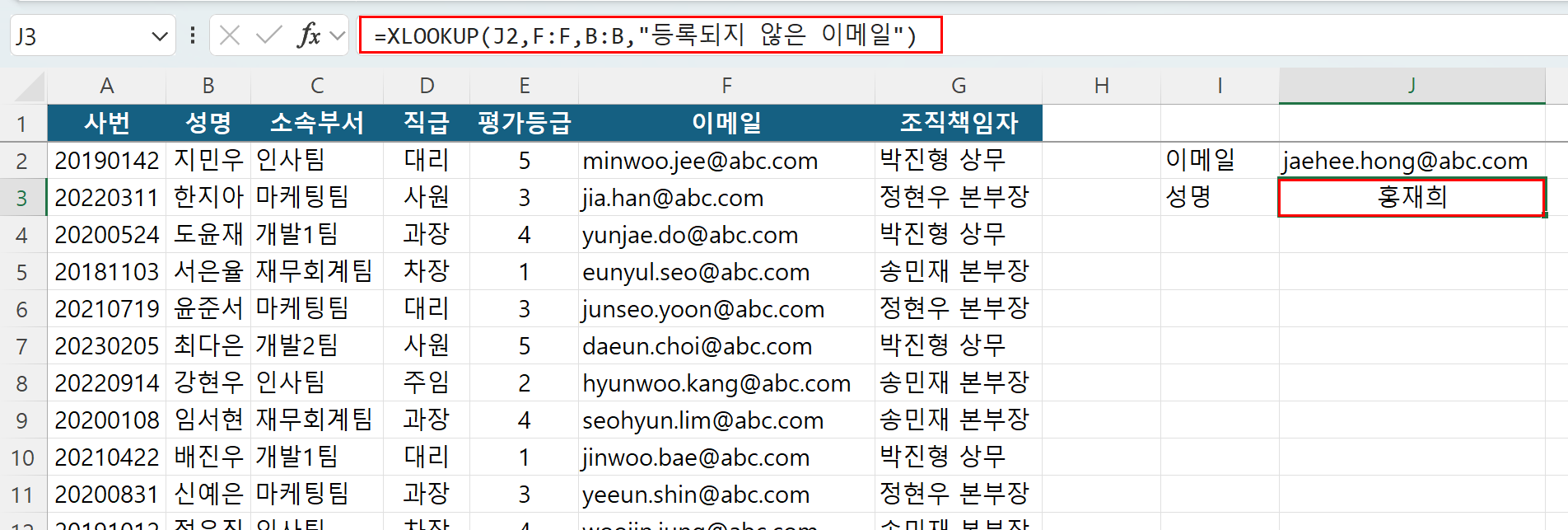
이 수식은 F열에서 해당 이메일을 빛의 속도로 검색한 뒤, 일치하는 행의 B열에서 성명을 정확히 찾아 반환합니다. 만약 명단에 없는 잘못된 이메일 주소라면, 지저분한 #N/A 에러를 표시하는 대신 "등록되지 않은 이메일"이라는 대체 텍스트를 출력합니다. 자체적인 에러 제어 기능 덕분에 수식이 훨씬 더 직관적이고 견고하게 작동합니다.
2. LET과 XLOOKUP 결합: 반복 계산을 없애 성능을 극대화하는 최적화 기법
보고서의 조건이 까다로워질수록 수식은 점점 더 길어지고 중첩 구조로 복잡해집니다. 특히 하나의 긴 수식 안에서 동일한 데이터 조회 계산을 두 번, 세 번 반복해서 실행해야 할 때 수식의 가독성은 바닥으로 떨어집니다. 더 큰 문제는 성능입니다. 엑셀은 수식 내에 적힌 동일한 XLOOKUP이나 VLOOKUP 함수를 매번 처음부터 다시 계산하기 때문에, 수만 행의 데이터가 있는 워크시트라면 처리 속도가 매우 느려질 수 있습니다.
이러한 계산 병목 현상을 해결해 주는 도구가 바로 LET 함수입니다. LET 함수는 프로그래밍 언어처럼 수식 내부에서 나만의 '변수'를 선언할 수 있게 도와줍니다. 즉, 컴퓨터에게 "이 복잡한 XLOOKUP 조행은 딱 한 번만 연산해서 '고과점수'라는 이름에 임시로 저장해 두고, 뒤의 조건문 수식에서는 계산기 다시 돌리지 말고 그 저장된 이름만 가져다 써!"라고 명령하는 것입니다. 한 번만 연산하므로 엑셀의 데이터 처리 부담이 드라마틱하게 줄어듭니다.
LET 함수의 기본 구문은 아래와 같이 직관적입니다.
=LET(name1, name_value1, [name2, name_value2], calculation)- name1: 첫 번째로 정의할 변수(계산 결과)의 이름입니다.
- name_value1: 실제로 연산할 수식이나 값(예: XLOOKUP 연산 등)입니다.
- calculation: 앞에서 정의한 변수 이름을 활용하여 수행할 최종 수식입니다.
실무 예제를 들어보겠습니다. 사원들의 연말 인사고과 평가 결과(`평가등급`)에 따라 최종 성과 등급 상태를 분류하는 업무가 주어졌습니다. 사번을 기준으로 조회한 평가등급 숫자가 5점이면 '최상위(S)', 1점이면 '역량개선(D)'으로 분류하고, 둘 다 아니라면 '일반'이라는 등급을 부여해야 합니다.
만약 LET 함수를 사용하지 않는다면 중첩된 IF 문과 반복되는 무거운 XLOOKUP 수식을 작성해야만 합니다.
=IF(XLOOKUP(A2, A:A, E:E)=5, "최상위(S)", IF(XLOOKUP(A2, A:A, E:E)=1, "역량개선(D)", "일반"))위 수식은 조건이 맞는지 비교할 때마다 매번 똑같은 사번 기반 XLOOKUP 조회를 중복 수행하므로 비효율적입니다. 하지만 LET 함수를 사용하여 XLOOKUP의 조회 결과를 '고과점수'라는 변수에 딱 한 번만 바인딩하면 수식이 매우 깔끔해집니다.
=LET(고과점수, XLOOKUP(A2, A:A, E:E), IF(고과점수=5, "최상위(S)", IF(고과점수=1, "역량개선(D)", "일반")))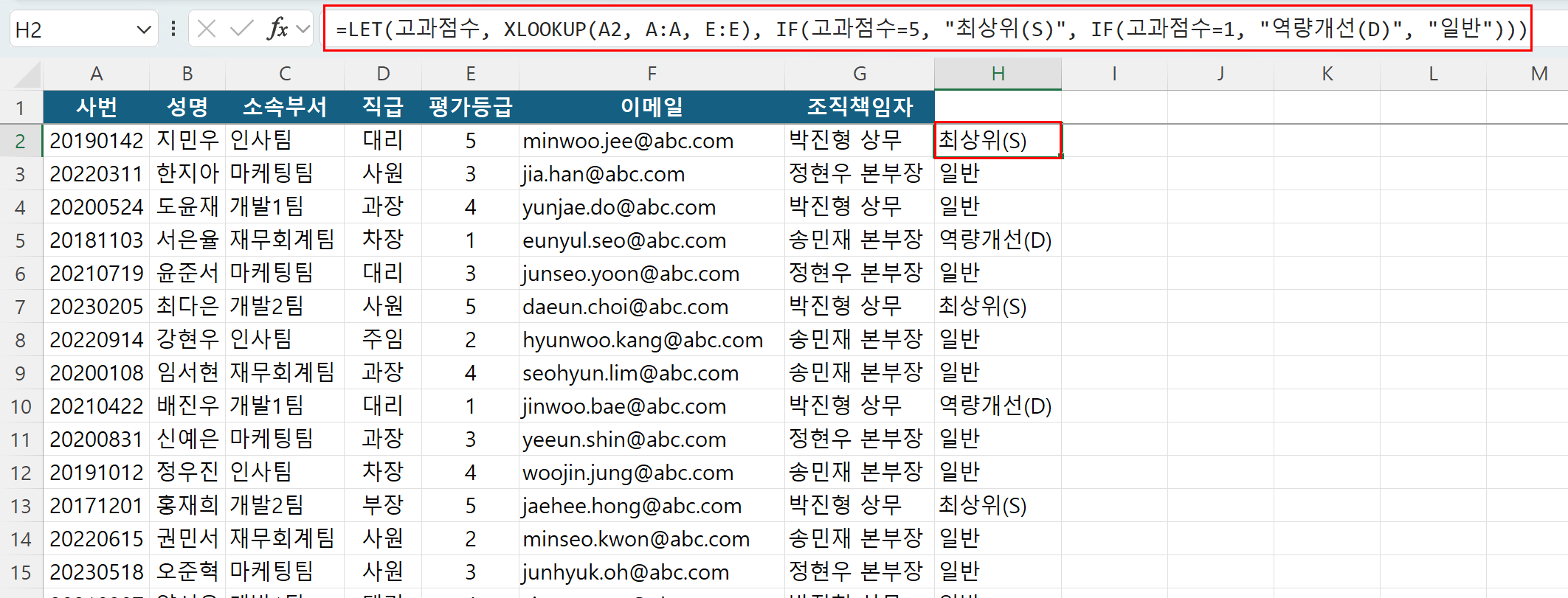
이 수식은 A2 셀의 사번을 기반으로 E열(평가등급)에서 숫자 평점을 단 한 번만 찾아 '고과점수'에 저장합니다. 그 후 중첩 IF 문에서는 엑셀이 재연산 없이 미리 기억해 둔 '고과점수'의 값만 비교하므로 데이터 처리 속도가 비약적으로 상승하며, 수식을 읽고 디버깅(오류 수정)하기가 훨씬 쉬워집니다.
3. INDEX와 MATCH 조합: 대용량 시트에서 속도로 압도하는 전통의 강자
최신 XLOOKUP 함수가 편리한 것은 사실이지만, 엑셀 전문가들이 수십만 행에 달하는 전사 마스터 데이터베이스를 다룰 때 여전히 고집하는 조합이 있습니다. 바로 INDEX와 MATCH 함수의 결합입니다. XLOOKUP이 출시되기 전까지 엑셀에서 최고의 조회 방식으로 애용되었으며, 현재까지도 사양이 낮은 PC 환경이나 행이 무수히 많은 초대형 스프레드시트에서는 최신 함수들을 제치고 독보적인 연산 속도와 가벼움을 자랑합니다.
이 조합이 극단적으로 빠른 이유는 수식의 작동 원리에 있습니다. 일반적인 조회 함수는 테이블 전체 범위나 여러 열을 모조리 메모리에 로드하여 탐색하지만, INDEX/MATCH 조합은 정확히 내가 조건을 검색할 '단 하나의 열'과 결과값을 가져올 '단 하나의 열'만을 조준하여 처리합니다. 불필요한 셀을 연산에서 완전히 배제하기 때문에 연산 부하가 최소화되는 겁니다.
두 함수는 각각 맡은 역할이 철저히 분담되어 있습니다. MATCH 함수는 지정된 범위 안에서 우리가 찾고자 하는 값이 '몇 번째 행'에 위치하는지 그 상대적인 위치(번호)만 찾아냅니다. 그리고 INDEX 함수는 MATCH가 가리켜 준 행 번호를 전달받아 원하는 결과 열에서 해당 위치의 실제 값을 핀셋으로 집어오듯 정확하게 가져옵니다.
구조를 이해하기 위해 먼저 위치를 찾아주는 MATCH 함수의 구문을 보겠습니다.
=MATCH(lookup_value, lookup_array, [match_type])정확히 일치하는 위치를 찾을 때는 반드시 마지막 [match_type] 인수에 0을 입력해야 합니다.
이어서 MATCH가 알아낸 위치 번호를 가지고 실제 데이터를 추출하는 INDEX 함수의 구문입니다.
=INDEX(array, row_num, [column_num])실무 적용 사례를 보겠습니다. 사번(A2)에 해당하는 직원의 '소속부서' 데이터를 C열에서 가장 가볍고 빠르게 찾아야 하는 상황입니다. 수식은 다음과 같이 결합됩니다.
=INDEX(C:C, MATCH(A2, A:A, 0))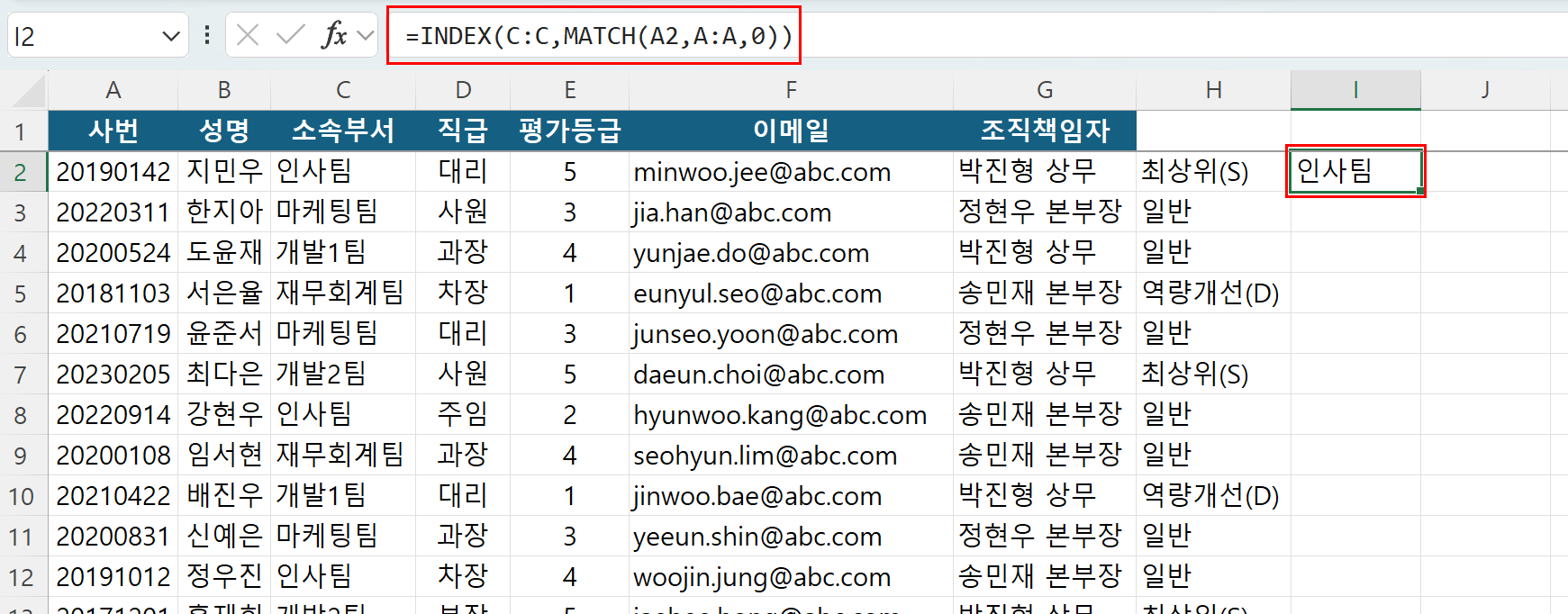
수식의 안쪽을 먼저 보세요. MATCH(A2, A:A, 0)가 A열 전체에서 A2 셀의 사번을 검색해 "이 직원은 2번째 행에 있습니다"라며 2라는 숫자를 반환합니다. 그러면 바깥쪽의 INDEX(C:C, 2)가 C열(소속부서)의 정확히 2번째 행으로 곧장 직행하여 '인사팀'이라는 값을 가져옵니다. 불필요한 다른 열들은 쳐다보지도 않기 때문에 대용량 파일에서 속도 저하 없이 신속하게 동작합니다.
4. FILTER: 다중 결과 목록을 한 번에 가져오는 동적 배열 함수
앞서 소개한 XLOOKUP이나 INDEX/MATCH를 포함한 전통적인 방식의 조회 수식들은 치명적이고 근본적인 한계점이 있습니다. 위에서부터 데이터를 검색해 내려오다가 조건에 일치하는 '첫 번째 데이터 딱 하나'만 발견하면 그 즉시 만족하고 검색을 완전히 중단한다는 점입니다. 하지만 실무에서는 "특정 본부장님이 관리하는 부하 직원 전원의 명단을 뽑아줘"처럼 조건에 부합하는 모든 레코드 목록이 필요할 때가 훨씬 많습니다.
과거 엑셀 2021 이전 버전에서는 이 문제를 풀기 위해 중괄호({ })가 들어간 아주 복잡한 배열 수식(Array Formula)을 작성해야만 했습니다. 하지만 이제는 혁신적인 FILTER 함수 덕분에 단 한 줄의 수식으로 원하는 조건의 데이터를 마치 체로 거르듯 몽땅 추출할 수 있게 되었습니다. FILTER 함수는 조건에 일치하는 데이터가 5개든, 100개든 상관없이 수식이 입력된 셀 아래쪽으로 결과 배열을 알아서 쪼르륵 펼쳐주는 '동적 배열(Dynamic Array)' 기술을 지원합니다. 행의 개수가 몇 개가 될지 미리 예측하고 수식을 하단으로 복사해 둘 필요가 전혀 없어 작업 시간이 압도적으로 절약됩니다.
FILTER 함수의 구문은 다음과 같이 매우 직관적입니다.
=FILTER(array, include, [if_empty])- array: 필터링을 거쳐 최종적으로 추출하고 싶은 전체 데이터 범위입니다. 단일 열은 물론, 여러 개의 열을 통째로 지정할 수도 있습니다.
- include: 참과 거짓을 판별할 논리 조건식입니다. 주로 '범위=조건'의 형태로 입력합니다.
- [if_empty]: (선택사항) 조건에 부합하는 데이터가 단 하나도 발견되지 않았을 때 대신 표시할 결과물입니다.
실무 적용 사례를 보겠습니다. 부서 보고를 위해 조직책임자가 "박진형 상무"인 산하 소속 직원들의 전체 명단 정보(성명, 소속부서, 직급)를 실시간으로 추출해 보고해야 합니다. FILTER 함수를 사용해 G열의 조직책임자가 "박진형 상무"인 행의 B열부터 D열까지의 데이터를 한 번에 가져오겠습니다.
=FILTER(B:D, G:G="박진형 상무", "해당 책임자 없음")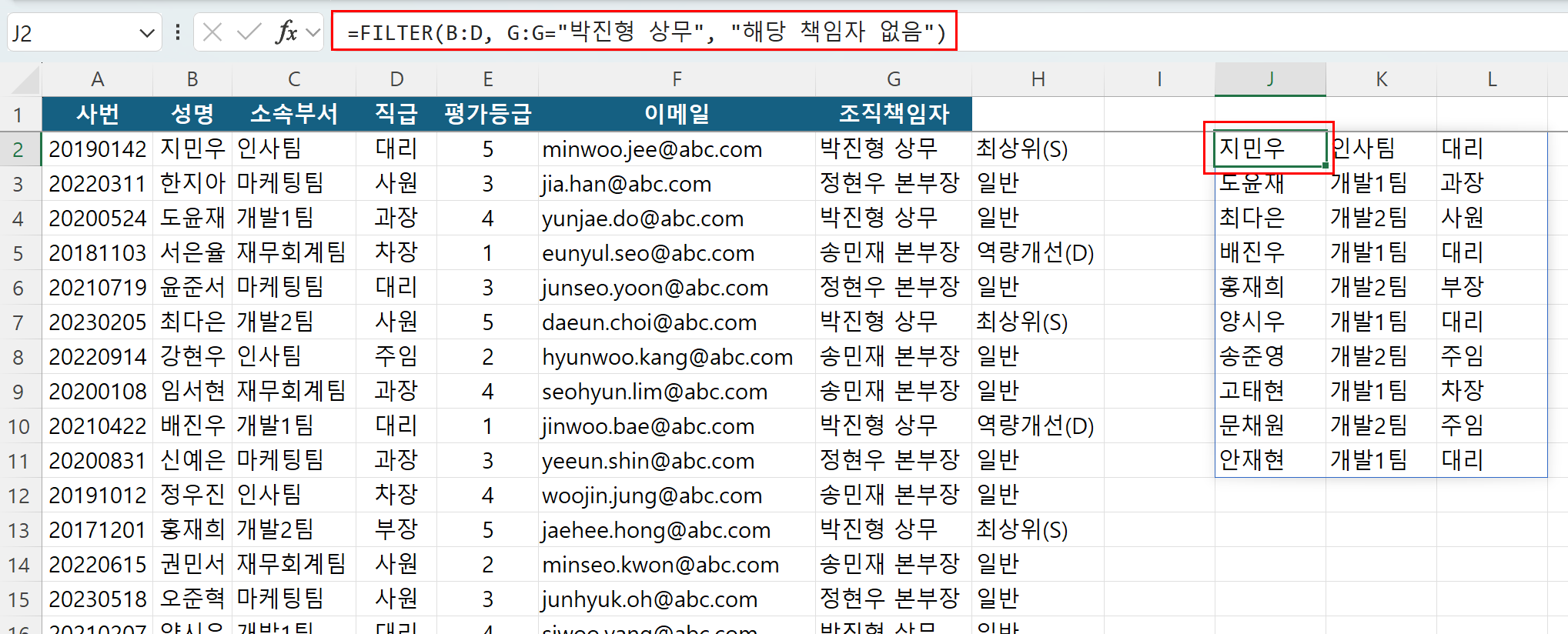
이 수식을 입력하고 엔터를 누르는 순간, 조건에 부합하는 직원들의 데이터가 수식 아래쪽 셀들로 자동 확장(Spill)되면서 깔끔하고 유연한 결과 표를 완성해 줍니다. 추후 원본 데이터에 새로운 직원이 추가되거나 조직이 개편되어 담당 책임자가 변경되더라도 결과 창의 표 크기가 스스로 연동되어 조절되므로, 매번 표 범위를 마우스로 드래그하여 수정하던 번거로운 수작업에서 완전히 해방될 수 있습니다.
💡 MVP TIP: 데이터 참조의 유연성 확보
초고속 조회 함수들을 실무에 배치할 때 성능을 한 단계 더 끌어올리는 비결이 있습니다. 수식 조건절에 특정 검색어 텍스트(예: "박진형 상무" 등)를 직접 하드코딩 형태로 적어 넣는 방식은 지양해야 합니다. 대신, 검색 조건을 입력할 빈 셀을 대시보드 상단에 하나 마련해 두고 수식에서 해당 셀 주소를 참조하도록 설계하세요. 그렇게 하면 데이터나 조회 대상이 바뀔 때마다 복잡한 수식을 일일이 뜯어고치지 않고 조건 셀의 입력값만 바꿔주면 수만 행의 데이터라도 실시간으로 갱신됩니다.
자주 묻는 질문 (FAQ)
Q1. 최신 XLOOKUP이나 FILTER 함수를 입력했는데 #NAME? 에러가 발생합니다.
#NAME? 오류는 엑셀이 해당 함수의 이름 자체를 인식하지 못할 때 발생합니다. XLOOKUP, LET, FILTER 함수 등은 오피스 365(Microsoft 365) 또는 엑셀 2021 이후 버전부터 공식 지원되는 최신 함수입니다. 만약 회사나 개인 PC에서 구버전 엑셀(2019, 2016 등)을 사용 중이시라면 이 함수들을 사용할 수 없습니다. 구버전 환경에서 호환성과 빠른 속도를 동시에 챙겨야 한다면 본문 3번에서 소개해 드린 INDEX와 MATCH 함수의 조합을 대안으로 적극적으로 활용하셔야 합니다.
Q2. FILTER 함수를 사용했는데 #SPILL! 이라는 생소한 에러가 뜹니다. 왜 그런가요?
#SPILL!(동적 배열 플러딩 오류)은 FILTER 함수가 조건에 맞는 결과 데이터를 아래쪽 셀들에 쫙 펼쳐서 뿌려주려고 하는데, 하필 그 아래 공간에 이미 다른 글자나 숫자가 채워져 있어서 진행을 방해받을 때 발생하는 에러입니다. 수식이 입력된 셀의 아래쪽과 오른쪽 주변 공간에 수식을 방해하는 기존 데이터나 텍스트가 입력되어 있지 않은지 확인하시고, 공간을 깨끗하게 비워주면 에러가 사라지면서 결과 목록이 정상적으로 출력됩니다.
Q3. 수식은 똑같이 썼는데 대용량 시트에서 속도가 여전히 느린 느낌입니다. 팁이 있나요?
조회 함수를 작성할 때 검색 대상 범위로 A:A 또는 F:F 처럼 열 전체를 통째로 지정하면 편리하지만, 수십만 행의 데이터가 엮여 있을 때는 엑셀이 데이터가 없는 빈 셀까지 전부 탐색 공간으로 인지하여 느려질 수 있습니다. 가급적 데이터가 입력된 실제 범위(예: $A$2:$A$31)로 범위를 제한하고 F4 키를 눌러 절대참조로 고정해 주는 것이 좋습니다. 혹은 원본 데이터를 [삽입] - [표] (Ctrl + T) 기능을 이용해 '엑셀 표' 구조로 변환한 뒤, 구조적 참조(예: 표1[사번]) 방식을 활용하면 데이터가 늘어나는 대로 범위가 최적화되어 가장 빠른 속도를 유지할 수 있습니다.
마치며
대용량 엑셀 스프레드시트의 연산 속도를 획기적으로 개선하고 칼퇴근을 도와주는 4가지 핵심 데이터 조회 접근법을 알아보았습니다. 복잡한 데이터 구조와 왼쪽 열 조회의 유연성이 필요할 때는 XLOOKUP을, 중복 계산을 없애 성능 가속화가 필요할 때는 LET 변수 지정을, 구버전 호환성과 압도적인 연산 경량화를 원할 때는 전통의 INDEX/MATCH를, 조건에 맞는 다중 행 결과 목록을 동적으로 추출할 때는 FILTER를 선택하시면 됩니다.
엑셀은 단순히 데이터를 모아두는 저장소가 아니라 수식의 설계 방식에 따라 수백 배의 가치를 발휘하는 강력한 자동화 도구입니다. 오늘 배운 초고속 조회 기술들을 여러분의 실제 업무 파일에 하나씩 차근차근 적용해 보시면서 스마트한 워크시트를 구축해 보세요.




