
지난번 통계청 가계조사(전국) 이미용 항목의 분기별 월평균 지출 자료에 대해 이어서 살펴보자.
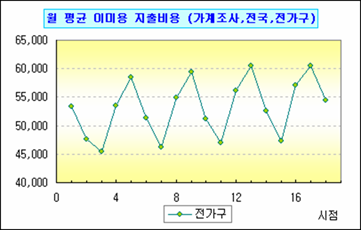
단순히 삼각함수로만 움직임을 나타내기에는 미심쩍은 부분이 있다. 이렇게 시계열 자료는 뭔지는 모르지만 무슨 섞어찌개 비슷하게 나타나서 사람을 아주 미치게 하는 마력(?)을 갖고 있다. 이에 미력한 재주로는 요인 모두를 색출해 내진 못하겠고, 하는 데까지만 해볼까 한다(아쉽지만 이후 작업은 많은 한계를 안고 간다는 것!).
어떤 분석을 하려면 기본적인 방향이 설정되어 있어야 되는데 시계열 자료는 아래 그림처럼 인식하고 요인들을 찾는 작업을 진행한다.
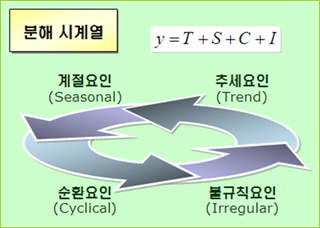
어떻게 보면 순리적인 구조가 아닐까 한다. 시간의 흐름과 연동되는 자료(시계열 자료)의 큰 추세를 확인하고 그 사이에 있는 계절성을 확인하고 그리고 계절성과는 또 다른 순환 구조를 확인한다는 게 말이다. 그런데 이 방법은 한계가 많다고 하는데 구조가 쉬워 애용된다(위 그림에서는 가법모형만 보여줬는데 승법모형도 있다(y=T*S*C*I).
이외에도 박스-제킨스 분석 방법도 있는데, 시계열 분석 책을 보니 위에 분해 시계열 분량이 1이라면 박스-제킨스 모형은 5 정도 분량을 차지하는 걸로 봐서 뭔가 신통한 효력이 있나 보다. 그러나 졸업하느라 다 놓고 나와 기억나는 것도 없고, 기억하고 싶지도 않은 게 솔직한 심정이다. 통상 ARIMA autoregressive integrated moving-average라고 하는데 혹 관심 있는 분은 참고하시기 바란다.
그리고 분해 시계열은 회귀분석의 연장선상에 놓여 있다고 봐도 무방할 정도로 회귀분석적(?)이다. 단지 독립변수가 t(시점)로 놓여진다는 게 다른 점일까.
서두가 길었는데 추세요인 부터 확인해보자.
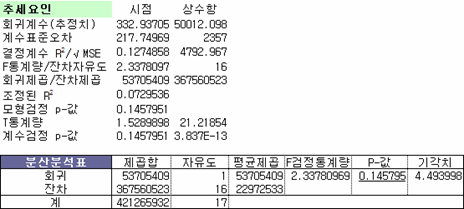
시점을 독립변수로 하여 LinEst 함수를 통해 구한 회귀모형의 결정계수를 확인해 보면 0.1275로 매우 낮게 나온다. 그리고 P-값은 0.1458 정도로 유의수준 0.05에서 회귀모형을 기각한다. 즉 1차 회귀모형은 적절치 않다는 결론 되겠다. 그럼 중회귀 2차로 넘어가고 2차도 기각되면 3차, 4차로 넘어가며 추세요인을 확인해야 된다. 그런데 개인적으로는 2차까지 해봐서 기각되면 추세요인을 제외시키고 다른 요인을 확인하는 게 정신건강에 이롭다고 본다.
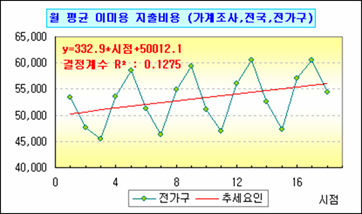
그러나 여기서는 혹시라도 다른 분들 참고하라고 그냥 살려두겠다. 그렇지만 통계적으로는 단연코 1차 회귀모형은 기각 됐다는 걸 오해하지 말기 바란다.
그리고 또 하나 토를 달 것이 있는데, 추세요인을 확인 할 때 '시점'을 사용하는 게 아니다. 몇 가지 문제가 발생되기에 직교 다항식을 사용해야 한다. 그런데 솔직히 다중공선성 문제 발생되는 거 빼면 그리 큰 문제라고 느껴지지 않기에 자체적으론(?) 그냥 '시점'의 1차, 2차, 3차를 사용한다. 그렇지만 원칙적으론 직교다항식을 사용해야 한다. 그래서 별도로 직교 다항식을 사용했을 때의 결정계수를 확인해 봤다.
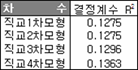
역시나 차수를 늘려도 결정계수가 영~ 흐느적 거리고 있다. 차수가 높을수록 결정계수도 함께 커지겠지만 이는 모수절약의 원칙을 위배하므로 적절치 못하다. 또 토를 달 게 있는데, 특히 돈과 관련된 자료는 오차항이 갖출 iid independent and identically distribute 성질을 위배하는 경우가 종종 있다(일반화선형회귀모형을 사용하는 이유와 비슷하지만 엑셀은 지원하지 않는다). 이 때는 대수 변환 후 처리하는데, 꼭 하라는 지시사항은 아니다. 그러나 잔차 확인 들어가 보면 대충 알게 된다. 다시 해야 된다는 걸.
아무튼 추세요인 결과로 얻은 기대값(기대값_추세)을 관찰값에서 뺀 잔차(잔차_추세)를 가지고 다시 확인한다.
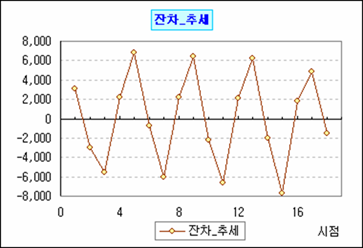
어째 원자료는 오르막이더구만 잔차_추세는 내리막이람? 이는 역으로 하나 마나한 작업을 위에서 했다는 얘기. 그렇지만 여기선 1차회귀를 강제로 인정하기로 했으니 Go Go!
이번엔 계절요인 확인이다. 지난 번에 숱한 역경(?)을 딛고 삼각함수를 이용했는데 더 쉬운 방법이 있다(이건 나만 알고 있으려고 했는데 ^^).
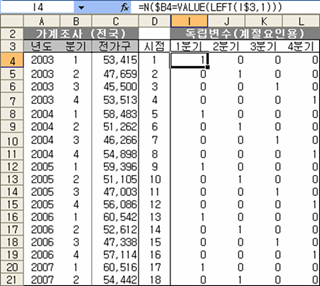
각 분기별 정보를 별도 자료(변수)로 지정하여 중회귀모형으로 분석하면 된다. 물론 LinEst 함수를 이용해서.
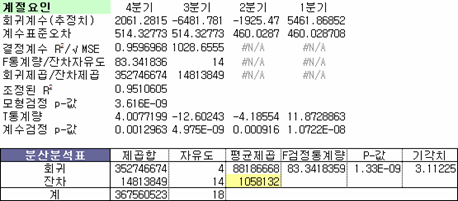
결정계수가 0.9597로 매우 높고, P-값 또한 1.33E-9로 매우 낮아 유의수준 0.05에서 회귀모형을 기각할 수 없기에 계절요인 추출과정이 끝났다.
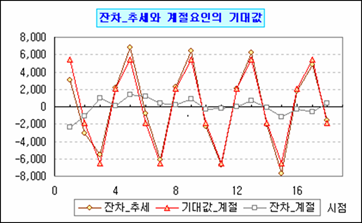
그럼 이제 삼각함수의 악몽에서 해방일까? 원 자료가 분기별 자료라 분기(변수)를 4개 밖에 사용하지 않았다. 만약 원 자료가 월 자료라면 월(변수)을 12개나 생성해 적용해야 되는데, 안 인간적이다. 안되는 건 아니지만 앞에서와 같이 모수절약의 원칙에 위배된다. 그래서 삼각함수를 이용한 모형을 같이 쓸 줄 알아야 한다.
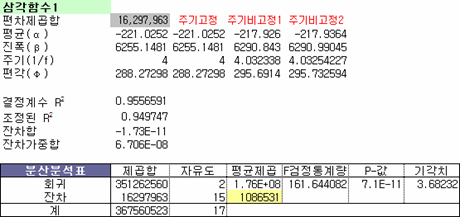
육안으로 봤을 때 뚜렷한 주기성이 느껴져 주기를 4로 고정했을 때와 고정하지 않았을 때로 나눠서 모의실험한 결과다. 위의 조건 모두 유의수준 0.05에서 유의미한 결과를 보여주지만 조금이라도 MSE가 낮은 주기비고정2 조건을 선택하겠다.
그리고 중간 위치에 잔차합, 잔차가중합이라고 있는데, 다른 모형들은 공식에 의해 계산된 결과이지만 이 경우는 모의실험을 통해 만들어진 결과이기에 잔차가 가져야 할 몇 가지 성질 중 기초적인 성질 두 가지가 만족될 수 있도록 하기 위해 해찾기 기능에 제한조건으로 추가했다.
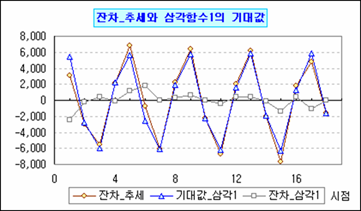
그런데 뭔가 어색하지 않나? '삼각함수1'이라고 한 게? 그렇다 '삼각함수2'도 있다. 참고로 삼각함수1, 2 모두 계절요인을 확인하는 과정이지만 혹시 혼동이 발생될까 싶어 달리 적었다. 지난 번에 살펴 본 삼각함수 모형을 조금 바꿔 본다면 아래처럼 된다.
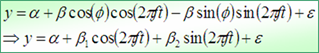
이는 독립변수를 만들어 LinEst 함수를 적용해 구한 회귀계수 추정치가 β1, β2 라는 거와 같겠다. 즉 모의실험이라는 고역을 거치지 않아도 회귀모형을 구할 수 있는 얘기다(요것도 나만 알고 있을까 했다 ^^).
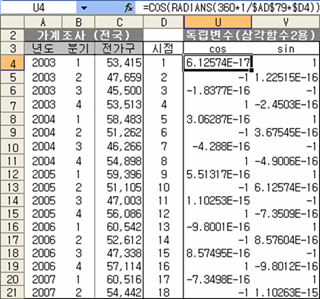
이렇게 독립변수를 생성한 다음 LInEst 결과를 정리해 보면,
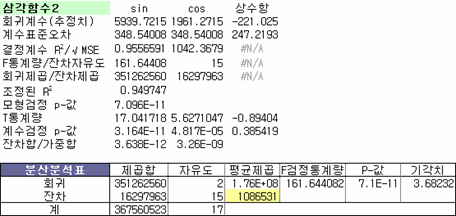
유의수준 0.05에서 유의미한 결과를 얻었다.
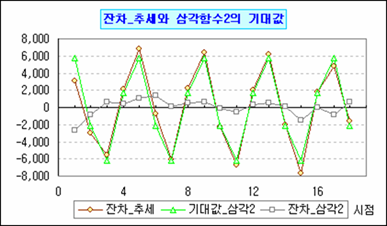
그리고 재밌는 건 모의실험 삼각함수1에서 주기를 4로 고정한 결과와 거의 같다. 그렇다면 삼각함수의 주기 및 편각의 역추정이 가능하다는 의미이다. 어디 계산해보자. β1=βcos(Φ) 이니까 먼저 진폭부터 구하고 그 다음 편각을 구하면 되겠다.
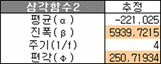
자, 이제는 확인만 하면 되는데... 어라 다르다. 몇 번을 계산했지만 모의실험 결과와 다르다. 뭘 잘못했나 싶어 다시 해봤지만 역시 다르다. 모의실험에서 구한 진폭을 갖다 붙여 계산해봐도 편각이 맞지를 않네? 몇 번을 훑어봐도 꼭 뭘 하나 놓친 기분인데 무엇인지 보이지가 않는다. 아니면 뭔가를 아예 잘못 생각하고 있는 건가?
그리고 딴 얘기지만, 잊지 말아야 하는 부분으로(이 글의 끝은 어디일까?)
추세요인 확인 후 계절요인 확인 시의 결과와 계절요인 확인 후 추세요인 확인 시의 결과는 서로 같지 않다(비직교성). 이것이 분해시계열의 한계가 아닐까 한다.
이제 남은 건 계절요인 제거 후 남은 잔차_계절(or 삼각1)을 대상으로 하는 순환요인. 그런데 아쉽게도 순환요인 처리하기엔 너무나도 계절성이 강했다. 즉 분석할 건더기가 남아있지 않았다는 것. 뭔 얘긴가 하면,
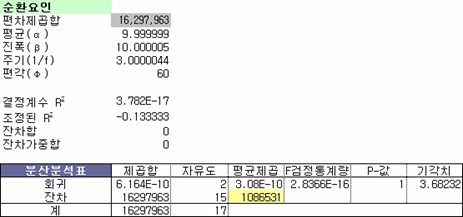
위에 결과는 유의미하지 않다는 것이지만 순환요인의 편차제곱합과 저 위에 삼각함수1의 편차제곱합을 확인해보면 서로 같다. 왜? 해찾기 기능의 한계일 수도 있지만 삼각함수1에서 이미 유의미한 경향을 찾아냈기 때문에 찾아낼 수 있는 순환요인이 남아 있지 않았다는 것. 또는 순환요인 자체가 없었을 수도 있다는 것이다. 그리고 순환요인은 상당히 긴 주기를 갖는 경향이 있어서, 왠 만큼 오랜 기간이 아니면 좀처럼 찾기가 힘든 것 같다.
불규칙요인은 오차항이라고 생각하면 된다. 즉 더 이상 규칙적인 요인은 남아 있지 않다는 의미이고, 이로써 분해 시계열은 종료된다. 참고로 불규칙요인이 진짜 불규칙한지 즉 무작위(Random) 한지를 검증하는 과정이 있으나 이는 건너 뛰겠다(통계 프로그램이 이럴 때 필요한 거다. 뭐가 이리 복잡한지...).
이로써 최종 모형은 아래와 같이 정리된다.

나라면 물론 고생은 했지만 단촐한 '추세+삼각1'을 이용할 것이다(아직도 삼각함수2가 미련이 남는다. 뭘 놓친거지?).
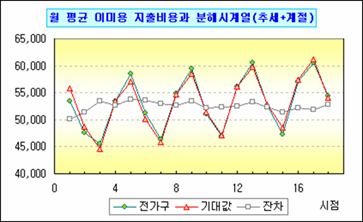
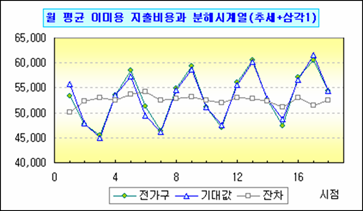
여기서는 다행히 계절성 덕분에 그나마 평이하게 분해 시계열 과정을 수행했으나 대부분의 자료에선 이렇게 쉽게 각각의 요인들을 끄집어 내는 건 생각만큼 쉽지 않다. 그리고 이런 모형 분석 과정은 분석자의 성향도 가미되는 바, 동일한 자료라도 똑같은 모형이 도출된다는 보장은 없다.
끝으로, 어설픈 정보를 보여드리게 되어 미안하게 생각한다. 혹 오류가 있다면 가르침을 바란다.





